Understanding the Problem
In order for two C++ assemblies to successfully communicate within the same process on any operating system, there are six key areas where direct compatibility needs to exist, or compatibility issues need to be handled, otherwise runtime errors can result. Each of these areas of compatibility build on each other, and all are required in order for a program to function. The image below shows the six different areas:
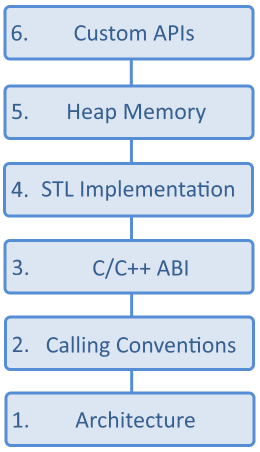
Each of these areas will be expanded on below.
1. Architecture
Architecture in this case refers to the processor microarchitecture your program is compiled to support. This determines the instruction set and machine code format your compiler emits when your program is compiled, such as x86, x64, or ARM. Basic instruction set compatibility is the most fundamental requirement for assemblies to communicate, and on many platforms a process cannot directly run any code that uses a different instruction set. On Microsoft Windows for example, beyond software emulation, a process which is compiled for the x64 architecture cannot load and execute code from assemblies compiled for x86, and vice versa.
The marshalling library doesn't attempt to solve any differences in the basic processor instruction set between assemblies.
2. Calling Conventions
Calling conventions relate to the mechanism by which data is organized and passed into and/or out of callable segments of code within a program. At a high level, C++ functions accept zero or more arguments in, and return zero or one values out. Although from a language level a function call in C++ is viewed as a single operation, numerous machine language instructions are emitted by the compiler to achieve this in the output program. A variety of storage mechanisms like registers, stacks, and memory buffers will exist on a given platform, and these will be used in various ways to pass data into or out of callable sections of code. Additionally, certain registers or areas of memory may potentially be overwritten or otherwise invalidated as a result of calling into another area of code. The set of rules governing the modification or retrieval of data as a result of a call is named a "calling convention".
Some platforms may have only a single standardized calling convention which is omitted by C++ compilers, for which compatibility is guaranteed into the future. In this case, compatibility isn't an issue. Some platforms however have a variety of calling conventions, and not all of these may be guaranteed to remain unchanged and compatible with previously compiled code. An awareness needs to exist of the calling conventions being used, and the guarantees and compatibility of those conventions, in order to be certain two assemblies can successfully call code from each other. As calling conventions are outside the scope of the C++ standard, and are inherently platform and in some cases vendor specific, documentation needs to be consulted for the particular target platform and/or compiler in use. One good thing to understand about calling conventions is that because at least one stable calling convention is a requirement in order for compatibility to be maintained, there will always be at least one stable calling convention per platform. Although calling conventions are outside the scope of the C++ standard, a requirement to be able to select between them for compatibility purposes means that vendor extensions are provided in compilers to change the calling conventions being used where required, usually in the form of custom compiler keywords that can be used on function declarations.
A full treatment of all the various calling conventions for different platforms and compiler vendors is beyond the scope of this documentation, but to summarize a few ones of key interest, on x64 PC platforms, a single standardized calling convention is in use on Windows, known as the "Microsoft x64 calling convention", and on Unix-related operating systems, the single calling convention defined by the "System V AMD64 ABI" is followed. This gives a guaranteed stable and compatible calling convention on these platforms without hassle.
Unlike the x64 architecture, if code is being compiled as x86 the situation is complex, with a variety of calling conventions provided on each platform, and even ones being named the same having differences of implementation even on the same platform between vendors. Custom keywords are available on each platform to override the default calling convention for functions, such as __cdecl, __stdcall, and __thiscall, where these keywords are ignored when compiling under x64 mode. On Microsoft Windows under Visual Studio, the __thiscall calling convention is the default for member functions, and is fully documented and stable, however it may not be supported on compilers from other vendors. Global functions outside a class default to the __cdecl calling convention, which is stable for each compiler vendor with itself, but does vary between vendors. For this reason, consideration should be given to defining exported global functions, and possibly exposed member functions too, using the __stdcall calling convention, which is standardized and supported by all vendors on Windows, being the calling convention used by the Windows API. Note that this calling convention doesn't support the ellipsis notation for defining variadic functions. The __fastcall calling convention must be avoided for all exported functions, being unstable and subject to change between compiler versions.
The marshalling library provides assistance with calling convention issues, providing a macro that can be used on functions in order to select the most appropriate calling convention for your platform, which can be used safely across assembly boundaries. The use of this macro is optional, and doesn't fully remove the need to be aware of the calling conventions available for your target platform, and the mechanisms by which they can be selected through your compiler. For further reading on the topic of calling conventions, please refer to the following references:
- https://en.wikipedia.org/wiki/X86_calling_conventions
- https://docs.microsoft.com/en-gb/cpp/cpp/calling-conventions
- https://docs.microsoft.com/en-gb/cpp/build/overview-of-x64-calling-conventions
- http://chamilo2.grenet.fr/inp/courses/ENSIMAG3MM1LDB/document/doc_abi_ia64.pdf
- http://www.agner.org/optimize/calling_conventions.pdf
3. C/C++ ABI
The C/C++ ABI, or Application Binary Interface, refers to the way high-level C++ concepts, types, and operations are expressed after compilation. It relates not only to the specific way code is compiled and the way data is organized and interacted with in the compiled code, it also relates to the way the program is structured and presented externally, such as the way exported functions are named and located. Unlike some other programming languages, the C++ standard places very few requirements on the way its high-level concepts end up being implemented. For example, there are no guarantees given around the size or structure of many of the native types (IE, int), and the way concepts like dynamic dispatch (virtual methods) are implemented is left up to the vendor. This gives a lot of flexibility for vendors to implement a feature in the most natural or efficient manner possible on a given platform, but it presents difficulties for code that is compiled separately and needs to interact, as the C++ standard itself gives no guarantees that two separately compiled code modules are able to communicate with each other, even if the same instruction set and calling conventions are being used.
One thing to realize is that no compiled C or C++ code can communicate without some basic level of ABI compatibility. Although vendors are left the flexibility to choose how they implement many features, practical reasons prevent breaking changes being made to fundamental points of implementation on any major platform after release. If the platform provides a C or C++ compatible API for example, the C/C++ ABI implementation must be mandated for that platform, and compatibility with it maintained forever for any features used as part of that API, otherwise all existing programs for that platform would cease to function. An exhaustive list of areas where C/C++ ABI compatibility must be maintained isn't always publicly documented for all platforms, however some information is usually provided, and further specific information can be inferred from the APIs provided on those platforms based on their own guarantees of compatibility and the ABI features they depend on to achieve that.
Under Visual Studio when compiling for Windows, there is a guarantee of "C" ABI compatibility between versions, and a guarantee of C++ ABI compatibility for the subset of the ABI required to support COM. For a documented acknowledgement of this fact, refer to the Overview of potential upgrade issues (Visual C++) article published by Microsoft. In this article under the "Toolset" section where the ABI compatibility policy is discussed, it is stated that "while the C++ ABI is not stable, the C ABI and the subset of the C++ ABI required for COM are stable". The "C" ABI compatibility guarantee was self-evident in the fact that the "C" API for Windows itself needs to maintain compatibility. The requirement for COM to maintain a stable C++ ABI subset is likewise obvious when you look at the way COM is implemented. The COM API was introduced in 1993, and constructs interfaces on request that need to be directly castable to C++ class definitions, which requires Windows and all C++ code compiled on Windows that can make use of COM to agree on the in-memory layout of instances of classes generated by COM. From a simple examination of COM, we can see that this subset of the C++ ABI must include the total layout of classes defined using single inheritance, and containing only pure virtual method definitions, and no data members. For example, the following class definition would be fully supported and guaranteed compatible by this ABI subset:
class ISomeBase
{
virtual int SomeBaseMethod() = 0;
};
class ISomeDerived : public ISomeBase
{
virtual int SomeDerivedMethod() = 0;
};This stable C++ ABI subset is very important, as it enables interface based programming on Microsoft Windows. Additionally, since all compiler vendors need to produce assemblies that are compatible with the operating system APIs, of which COM is a part, this C++ ABI subset is stable and common regardless of compiler version or vendor, as compatibility is guaranteed by the shared compatibility requirement on the OS-level COM API. Note that there are rules to follow to ensure compatibility of interfaces in this form between assemblies on Windows, which will be covered in detail in the following section on the solution.
On Unix-based systems, where open-source software is traditionally favoured over closed-source software, stable ABI guarantees are rarely provided by the operating system, as many programs are built from source by the users directly or distributed in pre-compiled form for a limited set of versions and distributions. Fortunately, common standards have emerged over the years, and today the Itanium C++ ABI, otherwise known as the Common Vendor ABI, is a readily available option which gives a guaranteed stable ABI implementation. By picking a common stable ABI such as this one when compiling assemblies, compatibility is assured for exchanging objects and interfaces, which is more than sufficient for the marshalling library to be used. Standards like the Itanium C++ ABI don't solve all the problems though, in particular STL implementation differences still occur and cause incompatibilities, which is where the marshalling library is able to help.
The marshalling library requires at least enough C ABI compatibility to successfully call an extern "C" function with each of the inbuilt primitive types, such as float, char, and int, and enough C++ ABI compatibility to exchange class definitions using only single inheritance and containing only pure virtual method definitions. As covered above, compatibility guarantees exist for these features on both Microsoft Windows and all the current major compilers for Unix-related operating systems. In cases where full C++ ABI compatibility doesn't exist such as on Windows, compatibility issues can be avoided through appropriate use of the marshalling library. For further reading on the topic of compiler ABI implementations, please refer to the following references:
- https://itanium-cxx-abi.github.io/cxx-abi/
- https://msdn.microsoft.com/en-us/library/mt743084.aspx
- https://blogs.msdn.microsoft.com/xiangfan/2012/02/06/c-under-the-hood/
- https://blogs.msdn.microsoft.com/oldnewthing/20040205-00/?p=40733
- https://randomascii.wordpress.com/2013/12/01/vc-2013-class-layout-change-and-wasted-space/
- https://chadaustin.me/cppinterface.html
- http://syrcose.ispras.ru/2009/files/02_paper.pdf
- https://isocpp.org/files/papers/n4028.pdf
4. STL Implementation
Even with a compatible architecture, calling convention, and C/C++ ABI, there's still a major barrier to compatibility in the form of the Standard Template Library. Like the rest of the C++ language, very few requirements are placed on vendors as to how the functionality of the STL must be implemented. Like all other objects however, unless two assemblies agree on the exact binary layout of STL objects in memory, they are incompatible. If you attempt to pass STL objects between two assemblies which share the same ABI, but have a different idea on the structure of those STL objects, you'll most likely trigger an assertion, crash, or corrupt the heap. This is the best-case scenario, the worst case scenario is that your program appears to run correctly, but produces an incorrect result or corrupts data.
Unfortunately, creating differing views of STL objects is incredibly easy to do. STL implementations will often change the structure of objects when compiling debug builds, in order to add extra debug checks and verification and catch runtime errors earlier, which can make debug and release builds incompatible. Many other compiler settings can also affect the structure of STL objects, depending on implementation. The changing nature of the C++ standard itself can also require breaking changes to object structures in order to satisfy new requirements, and the ever-present goals of improving efficiency and accelerating performance can lead to constant changes in implementation between versions. In current versions of MSVC for example, the std::string object contains a pointer to allocated memory to store the string content, but if the string length is 16 characters or less, the character data is encoded directly into the pointer, to save the memory allocation. This kind of micro-optimization can't be anticipated in advance, and can't be blocked forever into the future by compatibility requirements. For this reason, no vendors provide a stable ABI for the C++ STL.
There are two common approaches to solving this issue of STL compatibility:
- Share STL objects, and require all assemblies to be linked with the exact same compiler version and settings.
- Prohibit use of STL objects on exposed interfaces from assemblies. Do everything with "C-style" structures and native types.
Both of these approaches are massive compromises. Requiring all assemblies to use the exact same compiler version and settings is completely impractical in any kind of open plugin-based model. Only completely open-source projects, or closed source projects that are compiled in one go can even consider this option, and even then it is a significant limitation on growth and future direction of the project. Prohibiting the use of STL objects over the assembly API is a common solution, but it's also a potentially dangerous and crippling one for continued development. Without the use of STL objects, passing certain common structures between assemblies can become incredibly difficult. Consider the following function definitions:
std::string GetSchoolName();
bool GetClassNames(std::vector<std::string>& classNames);
bool GetStudentNamesInClass(const std::string& className, std::list<std::string>& studentsInClass);In this scenario, we have three functions provided. They are currently used internally inside an assembly, and we now want to expose them over a public API. Consider that all the above issues of compatibility have been addressed or don't apply, but we now have to deal with two incompatible STL implementations. Without the marshalling library, we'd have to adapt these functions to stop using STL types to obtain compatibility. Whether these functions are exported as extern "C" or members of an interface makes no difference. Let's see what that adaptation might look like. Here's one possible implementation:
const char* GetSchoolName();
int GetClassCount();
const char* GetClassName(int classNo);
int GetStudentCountInClass(int classNo);
const char* GetStudentNamesInClass(int classNo, int studentNo);The first thing to note here is that we had to totally change the way our functionality was exposed. Instead of three methods, we're now up to five. We've lost our boolean return value to indicate success or failure, and we now have to rely on a null pointer check for the returned character data, which is less obvious and easier to forget. We've also introduced three less obvious, massive problems though. The first one is we've just introduced serious memory allocation problems. Our implementation here returns string data as type const char* however. We've only returned a pointer to a block of memory, but that's not memory that the caller allocated, it was passed back from the called functions. The problem is though, we have no idea when the caller will be done with that memory. In order to prevent potential errors later on, that returned pointer must now stay valid forever, never being freed and its contents never changing, because our assembly has no idea when the caller will be done with it. Perhaps we provide some kind of global initialize and release methods to work around this, which the caller now need to remember to call at the appropriate times. Maybe we allocate some static buffers and store the data inside that, and record what events invalidate it, IE, perhaps there's only a single buffer for returning a student name, so the caller must copy the result of one call before making another. All of these options result in code that is harder to write, harder to verify, and more likely to have runtime errors than the original implementation that used STL objects.
The second major hidden issue we've created is that we've just made this code completely unsafe for use in a multithreaded environment. The previous implementation wasn't ideal, but could function to a reasonable degree with multiple concurrent threads through use of internal locking. Let's look at our memory allocation issue again though in the context of thread safety. It's not sufficient to just return a pointer to a block of static memory, because in a multithreaded environment, this data may change from another thread. Perhaps a class or student has its name changed on one thread, while another thread is trying to read the string. This will corrupt the data being read, possibly causing the reading thread to run off the end of the buffer and trigger a crash. What do we do now? Do we make our static buffers thread local, using up some of that valuable and limited resource for what should be a fairly simple and routine function call?
The third problem is that we've also potentially created a major performance issue here. Our original API had one function to return the names of all the students in the class in one request. There might have been a good reason for that design choice, maybe the function needs to retrieve that information from a slow external database link, possibly from a server running offsite. There could be considerable overhead and delay in making that request. Previously, a single request returned all the data to the caller, but now individual requests need to be made, one to obtain the number of students in the class, then another request per-student to retrieve the student name. Some kind of caching solution could be used to mitigate this problem, but it now becomes essential just to restore the equivalent performance that existed with the STL implementation.
Let's consider we wanted to address the memory allocation issue at the very least, but we were still stuck with not using STL objects. We might try and change our proposed implementation to something like this:
void GetSchoolName(char* buffer, int bufferSize, int& requiredBufferSize);
int GetClassCount();
bool GetClassName(int classNo, char* buffer, int bufferSize, int& requiredBufferSize);
int GetStudentCountInClass(int classNo);
bool GetStudentNamesInClass(int classNo, int studentNo, char* buffer, int bufferSize, int& requiredBufferSize);We've now made the caller responsible for allocating and freeing the string buffers, by having them pass in a pointer to a modifiable buffer and the current size of the buffer. Unfortunately, the caller has no idea how large a buffer is actually required. They could pre-allocate a large temporary buffer and copy the data back out to another one after the request, but they could never really know how large a buffer would be large enough, so to truly write safe and robust code, they'd need to be able to reallocate it if it turns out it was too small. We also need a way to tell the caller just how large the buffer needs to be, so we add a parameter to return the required buffer size to the caller. This solves our memory allocation problem, and marginally improves our threading situation, but it makes our performance problem worse, this time at the caller's end, and we've still taken a significant step backwards in thread safety, as we now can't retrieve the entire list of classes and students for classes without potential changes to that data while we're retrieving it. We've also created a disaster for the caller in terms of clarity and maintainability. Consider with our first implementation using STL types, we could have written a little program like this:
int main()
{
std::cout << "School name: " << GetSchoolName() << std::endl;
std::vector<std::string> classNames;
if (GetClassNames(classNames))
{
for (const std::string& className : classNames)
{
std::cout << "Class name: " << className << std::endl;
std::list<std::string> studentNames;
if (GetStudentNamesInClass(className, studentNames))
{
std::cout << "Enrolled students:" << std::endl;
for (const std::string& studentName : studentNames)
{
std::cout << studentName << std::endl;
}
}
}
}
return 0;
}With the proposed changes above around the caller allocating the buffer, equivalent calling code that correctly handles possible failures and buffer sizing requirements would look something like this:
int main()
{
std::vector<char> buffer(30);
int requiredBufferSize;
bool readData = false;
std::string schoolName;
while (!readData)
{
GetSchoolName(&buffer[0], buffer.size(), requiredBufferSize);
readData = (requiredBufferSize > buffer.size());
if (!readData)
{
buffer.resize(requiredBufferSize);
}
}
schoolName = &buffer[0];
std::cout << "School name: " << schoolName << std::endl;
std::vector<std::string> classNames;
int classCount = GetClassCount();
int currentClassNo = 0;
bool getClassNamesFailed = false;
while (currentClassNo < classCount)
{
readData = false;
while (!readData && !getClassNamesFailed)
{
if (!GetClassName(currentClassNo, &buffer[0], buffer.size(), requiredBufferSize))
{
getClassNamesFailed = true;
continue;
}
readData = (requiredBufferSize > buffer.size());
if (!readData)
{
buffer.resize(requiredBufferSize);
}
}
if (getClassNamesFailed)
{
continue;
}
classNames.push_back(&buffer[0]);
++currentClassNo;
}
if (!getClassNamesFailed)
{
for (int classNo = 0; classNo < classNames.size(); ++classNo)
{
std::cout << "Class name: " << classNames[classNo] << std::endl;
std::list<std::string> studentNames;
int studentCount = GetStudentCountInClass(classNo);
int currentStudentNo = 0;
bool getStudentNamesFailed = false;
while (currentStudentNo < studentCount)
{
readData = false;
while (!readData && !getStudentNamesFailed)
{
if (!GetStudentNamesInClass(classNo, currentStudentNo, &buffer[0], buffer.size(), requiredBufferSize))
{
getStudentNamesFailed = true;
continue;
}
readData = (requiredBufferSize > buffer.size());
if (!readData)
{
buffer.resize(requiredBufferSize);
}
}
if (getStudentNamesFailed)
{
continue;
}
studentNames.push_back(&buffer[0]);
++currentStudentNo;
}
if (!getStudentNamesFailed)
{
std::cout << "Enrolled students:" << std::endl;
for (const std::string& studentName : studentNames)
{
std::cout << studentName << std::endl;
}
}
}
}
return 0;
}Remembering that the resulting code here is still exposed to significantly more threading issues than the original code, is massively exposed to performance issues on both the caller and the implementation side, and is undeniably more likely to contain errors and harder to maintain, it's clear that not being able to use STL types on APIs like this between assemblies is crippling and severely detrimental to development. Additionally, if there is an existing API like this one currently in use within a codebase, trying to modify it to expose it as a shared API without STL types would require major refactoring work to the existing code usage, as this case highlights.
The marshalling library provides a comprehensive solution to this problem, that allows STL types to be passed across assembly boundaries with minimal overhead, and in most cases no changes to the calling code, and minimal changes to the implementation. Further information will be given in the following section on the solution.
5. Heap Memory
Even with the same platform, calling conventions, C/C++ ABI, and STL implementation, there's still yet another compatibility problem you encounter in C++, and that comes through heap memory allocation. Although two assemblies running within the same process can see the same memory, so pointers can safely be passed between them and memory read and written to, it's possible for two different assemblies to have different memory heaps. Heap memory is anything allocated through malloc, new, or similar approaches, and in C++ covers all allocated memory that's not on the stack. If all assemblies are compiled with the same version of the STL library, and that library is linked in the form of a separate assembly rather than a static library, the same memory heap will be used between assemblies. If two different versions of the STL are used between two assemblies however, as will generally be the case when different compiler versions are used to compile the assemblies, or if a statically linked C/C++ runtime is used, the memory heaps will differ between assemblies. This won't cause problems for allocating memory, but can cause major problems when releasing it. If memory is allocated in one module and is attempted to be freed in another, and a different memory heap is in use, an exception, heap damage, or memory corruption will result.
It is generally accepted in C/C++ that it's bad practice to free heap memory in a different assembly than where it was allocated. Principles of ownership strongly favour the same "entity" that allocated memory is the one that should free it. There are times when this principle is relaxed however, where issues around heap memory allocation and deallocation can arise. In C++11 for example, pointer types such as std::unique_ptr and std::shared_ptr are provided which specifically allow ownership of an allocated resource to be transferred during the lifetime of an object. Passing a pointer type such as these between assemblies potentially changes the assembly that attempts to deallocate any associated memory. There are also times when the use of STL types across assembly boundaries can cause heap memory allocation or deallocation, when it wouldn't be immediately obvious to the caller. For example, if STL objects are being shared across assembly boundaries, where the same STL implementation is in use but is linked in statically, passing any STL object that allocates heap memory such as std::vector, std::map, std::list, or most other STL types between those assemblies will cause heap issues very easily. If an object is passed over as a reference and is only read from in the other assembly, things work correctly, but if an object is modified across assembly boundaries, or if the object is passed by value with some calling conventions, attempts will be made to allocate or free memory on the wrong heap, causing a runtime error.
The marshalling library solves memory allocation problems when passing STL objects between assemblies, and provides tools to allow custom types to do the same. Additionally, support is given to assist with passing pointer types between assemblies where it is desirable to transfer object ownership from one assembly to another, without losing the safety of the Resource Acquisition Is Initialization (RAII) paradigm, or having to manually unpack and repack pointer types. More information on this will be given in the following section on the solution.
6. Custom APIs
The last area of compatibility to talk about involves custom APIs that are developed and provided by a given software application. This consists of not only functions and interfaces that form part of the software, but data types and structures that are exposed over APIs between assemblies. In our example above on the "STL Implementation", the functions listed to give access to school, class, and student information is an example of a custom API. Although these APIs are and will always be the responsibility of the developers writing the application, the marshalling library provides the ability to marshal custom types across assembly boundaries. This doesn't remove the ability of developers to create structures that have a fixed, known layout and are assumed to be compatible between assemblies, but it does allow the easy creation of custom types which don't have a fixed layout, but which can still be successfully marshalled between assemblies despite some layout differences. A custom type which is fixed from the application developer's point of view, but contains an STL type as one of its members, is a good example of where marshalling of custom objects might be used.
In addition to basic marshalling tools, some approaches, guidance, and suggestions on appropriate and safe methods of defining custom APIs for application development, in particular on how to extend these APIs and maintain backwards compatibility with existing code as your APIs evolve, will be given in the following section on the solution.